Искусственный интеллект теперь умеет применять кооперацию на недоступном людям уровне - «Технологии»

Новая впечатляющая победа искусственного интеллекта не просто над человеком, а над обладателями профессиональных навыков на их поле игры. ИИ «AlphaGo» впервые познакомился с командным шутером Quake III и после череды тренировок сумел последовательно победить всех соперников-людей, от рядовых до профи. Но что еще интереснее, никто не обучал его тонкостям игры, ИИ сам во всем разобрался и даже освоил кооперативный стиль на недоступном людям уровне.
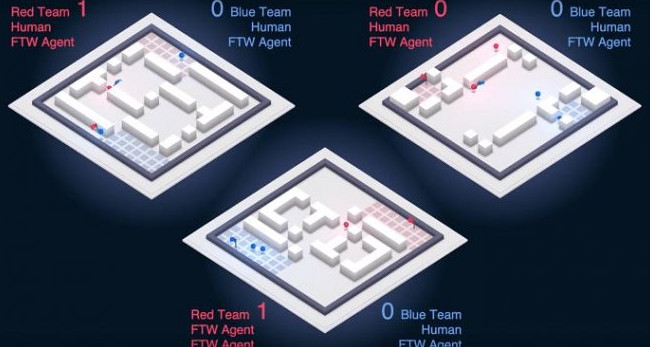
Испытания проходили в режиме игры «Захват флага». Нужно сразу отметить, что ИИ с ходу поставили в самое невыгодное положение, подключив к игровому интерфейсу без интерпретации данных. То есть, ИИ видел движущиеся на экране пиксели и знал всего один критерий успеха – помещение флага в определенную точку пространства. Понятия «друг», «враг», «база», «оборона», «контратака», даже наличие в игре оружия и способы его использования – все это AlphaGo логически вывел, наблюдая за процессом. Ему потребовалось 140 000 сеансов, чтобы методом проб и ошибок освоиться в игре на уровне обычного геймера.
Но дальше все пошло куда лучше — уже после 175 000 тренировок ИИ начал стабильно обыгрывать профессиональных игроков. После 400 000 сыгранных матчей лучшая сыгранная пара геймеров, которые 12 часов изучали стиль AlphaGo, а во время состязания активно общались между собой, в итоге проиграли ему со счетом 1:4. Другие команды уступали ИИ с разницей в 16 флагов, а по результатам турнира почти сорок человек признали AlphaGo «лучшим напарником», чем игроки-люди.
Отметим, что в игре участвовала новая версия AlphaGo, с двойным уровнем «мышления»: аналитическим, для выработки стратегии, и практическим, для принятия сиюминутных решений. Первый он применил, когда придумал, а потом забраковал несколько тактик, а при помощи второго создал собственные маркеры и детекторы важных объектов и событий в игре. Пытаясь усложнить задачу, исследователи понизили точность стрельбы ИИ с 80 % до 50%, а время отклика растянули до 267 мс, чтобы нивелировать превосходство в скорости обработки информации перед живым человеком. Это не помогло – AlphaGo все равно выиграл.
Самый интригующий факт: лучшей комбинацией в игре «захват флага» стал дуэт человека и ИИ, причем они не контактировали между собой и не согласовывали свои действия. Оказалось, что ИИ проще подстраивать свою тактику под действия ведущего-человека, чем организовывать работу двух ИИ-игроков. И пусть разница между парами составила всего 5%, но она налицо. Наш мир приближается к эпохе создания идеальных роботов-напарников для людей.
И будьте в курсе первыми!